Come tutti sappiamo, la fine del 1980 non ha rappresentato solamente il momento in cui i Guns N’ Roses hanno raggiunto il successo e Madonna e Michael Jackson si sono esibiti nei loro iconici tour mondiali, ma (forse) il momento più importante è stato rappresentato dall’apparizione di ITIL. Grazie a questo nuovo framework, l’IT ha potuto iniziare a fornire Servizi e non tecnologia ai propri user e clienti. Tutti concordano sul fatto che le interruzioni di servizio sono fattori negativi che devono essere risolti il prima possibile. Torneremo dopo su questi due aspetti, e vedremo perché sono la causa di tutti i mali.
Quando compare un problema
Il problema potrebbe apparire come se dovesse essere gestito da uno psicologo invece che da un professionista IT: noi, esseri umani, troviamo estremamente difficile lasciare un dolore evidente senza risposta, anche se abbiamo la promessa di un successivo miglioramento. Se ci pensi, questa è proprio l’origine del catch 22.
Il catch 22 è una situazione paradossale da cui un individuo non può scappare a causa di regole o limitazioni contraddittorie.
Nell’implementare le best practice di ITIL in un’organizzazione, istituiamo delle Pratiche (che in ITIL v3 erano chiamate Processi) perché vogliamo:
- essere più efficienti
- essere più strutturati
- ottenere controllo sulla nostra infrastruttura
- risparmiare soldi
- aumentare la soddisfazione dei clienti
Per approfondire, leggi il nostro articolo Consigli per implementare ITIL in un’organizzazione.
Il catch ventidue: cos’è?
Anche se l’obiettivo ultimo di tutte le Pratiche è quello di soddisfare i nostri clienti, alcune di queste sono più orientate agli user rispetto ad altre. Qui è dove iniziano i Problemi: investiamo tutte le nostre risorse nelle Pratiche più orientate all’user e questo ci lascia disarmati quando dovremmo investire tempo ed energie in Pratiche meno user-facing ma ugualmente, o forse anche più, importanti.
Focalizzarsi sulle Pratiche orientate agli user è una scelta ovvia. Quando gli user mettono il Service Desk sotto pressione, o quando un incidente impatta la produzione, o quando i clienti stanno aspettando la prossima versione del prodotto, vuoi intraprendere le attività necessarie. È umanamente molto difficile (in alcune situazioni direi impossibile) respingere queste attività in favore di quelle che non avranno un effetto immediato.
Come risultato, finiamo per investire tutto il nostro tempo e le nostre energie a combattere degli incendi, senza avere neanche il tempo di chiedere a noi stessi come sia possibile avere così tanti incendi da domare. E qui troviamo il nostro catch 22: le interruzioni di servizio (Incidenti) sono eventi negativi e andrebbero risolti il prima possibile. Ci concentriamo così tanto sulla seconda parte della frase, che ci dimentichiamo la prima.
Se concordiamo sul fatto che gli Incidenti siano fattori negativi, che hanno un impatto molto negativo sulla soddisfazione dei clienti, allora dovremmo cercare di evitarli, no? E se non possiamo evitarli completamente, uno degli obiettivi del Problem Management è sicuramente quello di minimizzarne l’impatto. Concordiamo tutti su questo, ma è più facile a dirsi che a farsi, perché siamo umani e quindi veniamo catalizzati dalla parte “risolvere il prima possibile” della frase.
Non una soluzione magica, ma…
Quindi non c’è via di scampo? Siamo condannati a rincorrere i mulini a vento? Per fortuna no. Ma come già detto, non c’è una soluzione magica. O almeno, nessuna che io conosca (se tu ne hai una per le mani, non esitare a condividerla con noi), ma possiamo lavorarci!
In una situazione ideale, si potrebbe pensare, un’organizzazione dovrebbe avere due team separati per lavorare su Incidenti e Problemi, così da poter evitare di essere risucchiati dal catch 22. Tuttavia, non sempre le cose sono così semplici.
Incidenti e Problemi sono strettamente collegati
La prima motivazione in mente è quella di giustificare l’impossibilità di team separati, è perché non si hanno a disposizione abbastanza professionisti per dedicare un team alla sola attività di risoluzione Problemi. Se questo è vero nella maggior parte delle situazioni, probabilmente non separeremmo queste due attività in ogni caso, perché sono strettamente collegate.
Infatti, la conoscenza tecnica e le competenze necessarie sono strettamente collegate. Uno impara molte cose utili per risolvere Problemi e documentare i Workaround, mentre l’altro lavora sugli Incidenti, e viceversa. Quindi gruppi completamente separati non è la soluzione migliore, ma potrebbero esserlo i gruppi temporanei. Infatti, formare un gruppo temporaneo (che comprenda le giuste competenze) su uno o più Problemi dovrebbe evitare ai membri del team l’ansia che deriva dalla gestione di Incidenti, a condizione che il team possa lavorare in un posto dedicato.
Implementazione chiara delle tre fasi del Problem Management
Una chiara implementazione delle tre fasi del Problem Management, come suggerito in ITIL 4, può aiutarti ad andare nella giusta direzione. Poiché ogni fase ha un output ben definito, è relativamente facile affidare le diverse fasi a gruppi diversi, questo può anche essere un buon modo di suddividere il carico di lavoro.
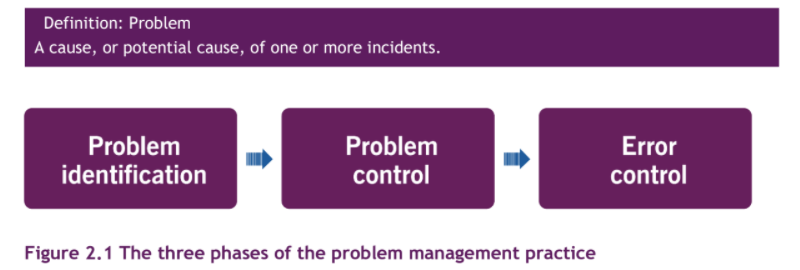
1. Fase di identificazione del Problema, sia proattiva che reattiva, questa fase dovrebbe, secondo la mia opinione, essere svolta da professionisti che abbiano competenze sia tecniche che funzionali. Dovrebbero avere una buona conoscenza dell’organizzazione e anche una visione chiara delle infrastrutture tecniche su cui si basano i nostri servizi. Entrambi sono necessari per individuare la presenza di potenziali Problemi e quindi produrre gli output richiesti: documentazione completa e dettagliata dei Problemi (Problem record).
Una prioritizzazione del Problem record dovrebbe avvenire tra la fase di Identificazione dei Problemi e quella di Controllo. Questo è essenziale per ridurre lo stress (c’è sempre troppo da fare) e assicurare che facciamo il miglior uso possibile delle nostre risorse limitate.
2. Fase di Controllo del Problema, dovrebbe essere realizzata da tecnici con esperienza, creativi e di ampie vedute. A partire dal Problem record, analizzano i problemi e documentano quanto rilevato. Questo porterà i Problemi allo stato di Errore Noto (Known Error). Gli output attesi da questa seconda fase sono soluzioni per il flusso di lavoro, che aiuteranno a risolvere gli Incidenti più velocemente (e questo migliora la soddisfazione dell’user e lascia un po’ di tempo libero al nostro staff tecnico, lasciando intravedere la fine del catch 22).
3. Error Control è la terza ed ultima fase delle Pratiche di Problem Management. Un’attività importante di questa fase è, ancora una volta, un’attività di prioritizzazione. Poiché i Known Error possono rimanere aperti per un po’ di tempo, e le circostanze sono destinate a cambiare, questa attività di prioritizzazione dovrebbe tenersi a cadenze regolari. La priorità degli Errori Noti dovrebbe essere valutata da un team di professionisti. Infatti, devono essere tenuti in considerazione diversi criteri, come ad esempio:
- impatto sulla soddisfazione dei clienti
- costo dell’applicazione dell’attuale Workaround
- costo della risoluzione definitiva
- fattibilità tecnica della risoluzione definitiva
- influenza sui prodotti partner che stiamo usando
Una volta che i Known Error sono prioritizzati, il lavoro può iniziare su una risoluzione definitiva o sul miglioramento Workaround.
Speriamo che questo approccio strutturato al Problem Management possa ispirarti abbastanza da convincerti ad adattarlo alla tua stessa organizzazione, così da farti uscire dal “catch 22 del Problem Management”.








